
Unity ML-Agents toolkit is a new plugin based on the game engine Unity that allows us to use the Unity Game Engine as an environment builder to train agents.
From playing football, learning to walk, to jumping big walls, to training a cute doggy to catch sticks, Unity ML-Agents Toolkit provides a ton of amazing pre-made environments.
Furthermore, we can also create new learning environments.
How Unity ML-Agents works?
Unity ML-Agents is a new plugin for the game engine Unity that allows us to create or use pre-made environments to train our agents.
The three components
With Unity ML-Agents, we have three important components.
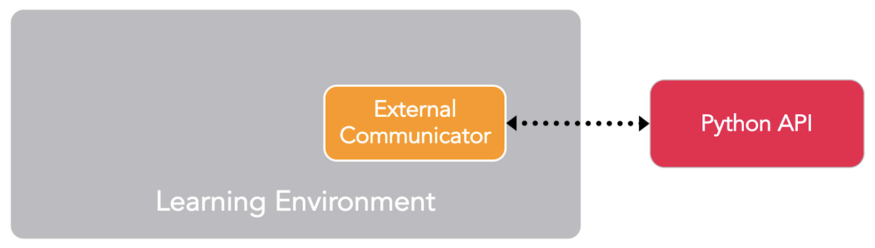
Source: Unity ML-Agents Documentation
The first is the Learning Environment (on Unity), that contains the Unity scene and the environment elements.
The second is the Python API that contains the (Reinforcement Learning) RL algorithms (such as PPO and SAC). We use this API to launch training, to test, etc. It communicates with the Learning environment through the third component called external communicator.
Inside the Learning Environment
Inside the Learning Environment, we have different elements:
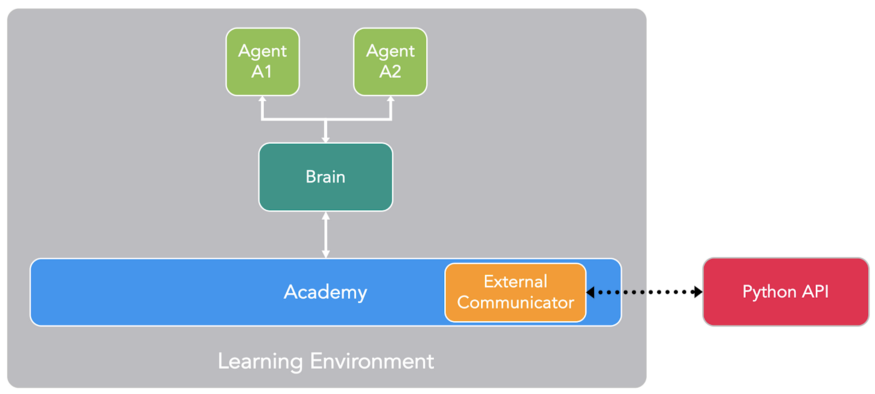
Source: Unity ML-Agents Documentation
The first is the Agent, the actor of the scene. It’s him that we’re going to train by optimizing his policy (that will tell us what action to take at each state) called Brain.
Finally, there is the Academy, this element orchestrates agents and their decision-making process. Think of this Academy as a maestro that handles the requests from the python API.
To better understand its role let’s remember the RL process. This can be modeled as a loop that works like this:
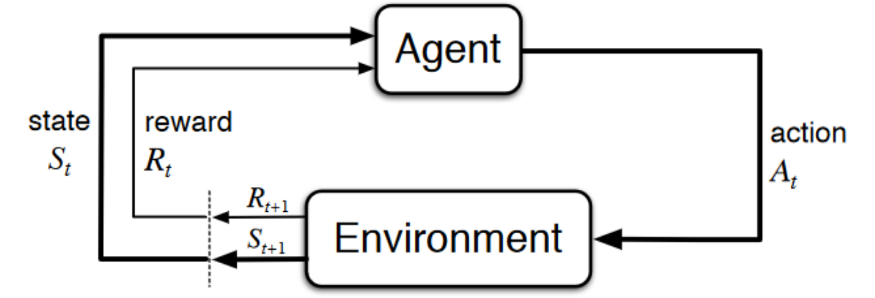
Source: Sutton’s Book
Now, let’s imagine an agent learning to play a platform game. The RL process looks like this:
- Our agent receives state S0 from the environment — we receive the first frame of our game (environment).
- Based on the state S0, the agent takes an action A0 — our agent will move to the right.
- The environment transitions to a new state S1.
- Give a reward R1 to the agent — we’re not dead (Positive Reward +1).
This RL loop outputs a sequence of state, action, and reward. The goal of the agent is to maximize the expected cumulative reward.
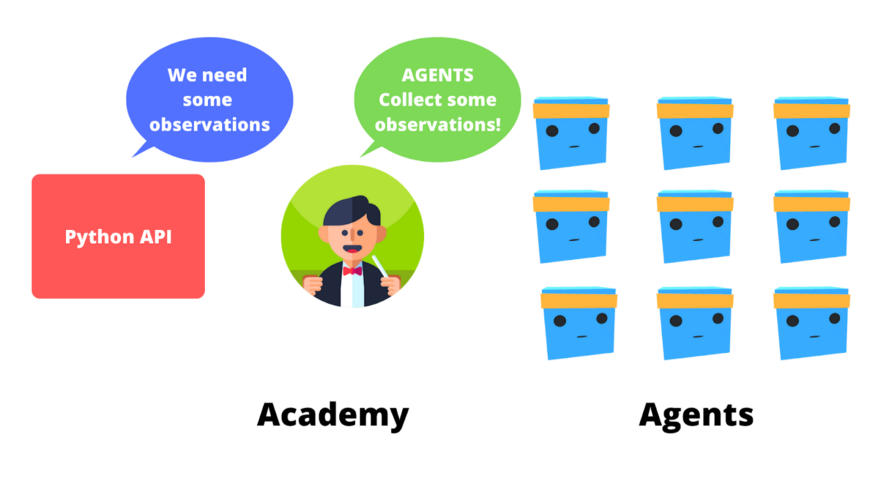
In fact, the Academy will be the one that will send the order to our Agents and ensure that agents are in sync. It will also perform these actions:
- Collect Observations
- Select your action using your policy
- Take the Action
- Reset if you reached the max step or if you’re done
In next post, we will explain in detail how to train agents for various scenarios. Stay tuned.